
技術と「非合理(ノイズ)」のハイブリッド学習
— きれいに学ぶほど弱くなる? “わざと揺らす”が強さを作る
AIやソフトウェア設計の世界では、つい「正確・最適・再現性」を目指しがちです。
でも現実は、曖昧さ・偶然・気分・環境差など“ノイズ”だらけ。にもかかわらず、私たち人間はそのノイズの中でそこそこ上手く判断し、学び、適応しています。
このギャップを埋める考え方が、ここでいう 「技術 × 非合理(ノイズ)」のハイブリッド学習です。
- 技術(合理):データ、アルゴリズム、評価指標、最適化、再現性
- 非合理(ノイズ):揺らぎ、ランダム性、探索、誤差、人間の直感、偶然の発見
ポイントは「ノイズを排除する」ではなく、ノイズを“設計して混ぜる”こと。
これが、汎化性能(初見への強さ)やロバスト性(壊れにくさ)を引き上げ、時に“創発”まで生みます。
1. なぜノイズが学習を強くするのか(直感的な説明)
ノイズを混ぜると、学習は一見“いい加減”になります。ところが、次の3つが起こります。
(1) 「丸暗記」を阻止して、汎化を促す
データが少ない・偏っている状況で、モデルは簡単に“暗記”します。
ノイズは暗記を邪魔し、本質的な特徴だけを掴ませる方向に働きます。
(2) 現実のズレ(分布シフト)に耐える
現実では「学習時と同じ条件」はほぼありません。
入力に揺らぎを与えて訓練すると、モデルは揺れても崩れない解を好むようになります。
(3) 探索が増えて、思わぬ当たりを引く
最適化は放っておくと「近くの山(局所最適)」にハマりがち。
ノイズがあると探索が増え、より良い解へ抜ける可能性が上がります。
2. “設計された非合理”の代表パターン(AI/ML編)
ここからは「ノイズを良い形で入れる」具体例を並べます。
大事なのは、ノイズ=ランダムではなく、目的に沿って制御すること。
パターンA:入力にノイズ(Data Augmentation / Noise Injection)
- 画像:回転、切り抜き、色変換、ガウシアンノイズ
- 音声:ピッチ変更、環境音混合
- テキスト:単語ドロップ、パラフレーズ
効く理由:現実の“見え方の違い”を擬似的に経験させ、過学習を減らす。
パターンB:モデル内部にノイズ(Dropout / Stochastic Depth)
- Dropout:一部のニューロンをランダムに無効化
- Stochastic Depth:層をランダムにスキップ
効く理由:特定経路への依存を減らし、冗長で強い表現を作る。
パターンC:最適化にノイズ(SGDの揺らぎ / ラベルスムージング)
- SGDのミニバッチはもともと“ノイズを含む勾配”
- ラベルスムージング:正解ラベルを少し曖昧にする
効く理由:決め打ちの鋭い境界より、滑らかで再現性のある境界を好む。
パターンD:探索にノイズ(ε-greedy / 温度付きサンプリング)
- 強化学習:行動をランダムに混ぜる
- 生成AI:temperature / top-p による多様性制御
効く理由:探索がないと改善が止まる。“たまの寄り道”がブレイクスルーになる。
3. “技術×非合理”をプロダクト学習に落とす(チーム/運用編)
ハイブリッド学習は、AIだけでなく組織やプロダクトにも効きます。
(1) A/Bテストに「探索枠」を残す
改善を数字で回す(合理)一方で、
一定割合は“勝ち筋不明の案”に割り当てる(非合理)。
- 例:80%は確実改善、20%は冒険枠(新UI/新導線/新コピー)
- 結果:短期最適と長期成長を両立しやすい
(2) “ノイズのログ”を取る(失敗や例外を資産化)
-
例外、手戻り、炎上、問い合わせ…はノイズの塊
でも、そこに改善の種が詰まっています。
おすすめ:
「例外を“なかったこと”にしない」ために、
例外ログ → 分類 → 再発防止(or 意図的に残す)までをパイプライン化。
(3) 人間の直感を“検証可能な形”に変換する
「なんとなくこっち」も価値はあります。
ただし、最強なのは 直感 → 仮説 → 計測 の変換ができる状態。
4. 実装イメージ:ノイズを“つまみ”として設計する
ハイブリッド学習が失敗する典型はこれです。
- ノイズが多すぎて収束しない
- ノイズが少なすぎて効果が出ない
- 目的がなく“ただランダム”になっている
そこで、ノイズは **つまみ(ハイパーパラメータ)**として設計します。
ノイズ設計のチェックリスト
- ノイズの目的は何か?(汎化?探索?ロバスト?創造性?)
- 入れる場所はどこか?(入力/モデル内部/最適化/意思決定)
- 強度は調整可能か?(学習初期だけ強く→後半弱める等)
- 評価はどうするか?(精度だけでなく、分布シフト耐性も見る)
擬似コード例(ノイズ強度をスケジュール)
for epoch in 1..E: noise = schedule(epoch) # 例:最初強く、後半弱く x_tilde = augment(x, noise) y_pred = model(x_tilde, dropout_rate=noise) loss = criterion(y_pred, y, label_smoothing=noise) update(model, loss)5. 画像で理解する(記事内の図案)
図1:合理とノイズの役割分担(概念図)
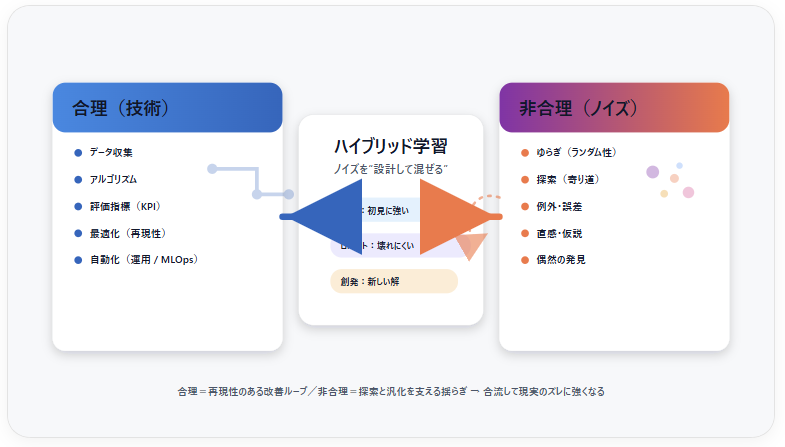
図の内容
- 左:合理(データ→学習→評価→改善)
- 右:非合理(揺らぎ・探索・偶然)
- 中央:合流して“ロバスト学習”へ
図2:ノイズ量と性能の関係(イメージ曲線)
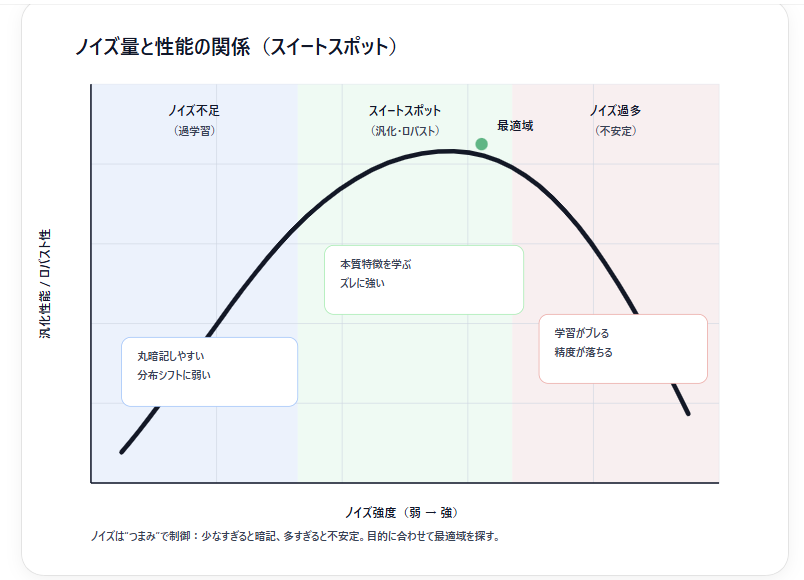
説明文(キャプション案)
「ノイズは少なすぎても効かず、多すぎると壊れる。最適域(スイートスポット)を探すのが設計。」
図の内容
- 横軸:ノイズ強度
- 縦軸:汎化性能
- 山なりの曲線(最適域がある)
まとめ:ノイズを敵にせず、“道具”にする
- ノイズは学習を弱めるどころか、暗記を減らし、ズレに強くし、探索を増やす
- 重要なのは「ランダムにする」ではなく、目的を持って制御する
- AIだけでなく、プロダクト改善やチーム運営でも同じ発想が使える
合理(技術)だけだと、賢いけど脆い。
非合理(ノイズ)だけだと、面白いけど当たらない。
だからこそ、その間を設計する “ハイブリッド学習” が効きます。








