この記事でわかること
- GPT‑OSS(オープンソースLLM)の基礎
- LM Studio の特徴と導入手順(Windows / macOS)
- 失敗しないモデル選び(軽量〜高性能)
- 実運用に近い使い方:ローカルAPI化、エディタ連携
- パフォーマンス・トラブル対策
- そのまま使えるプロンプト集&画像案

GPT‑OSS とは?
GPT‑OSS は、商用APIに依存せず、だれでも入手・改変・再配布できる オープンソース/開放ライセンスの大規模言語モデル(LLM)の総称です。代表的な系統は次のとおり。
- Llama 3 系(Meta): バランスがよく用途広め
- Mistral / Mixtral(Mistral AI): 速度と品質のバランス、MoE版は長文が得意
- Phi‑3(Microsoft): 小型でも賢い、省リソース
- Qwen(Alibaba): 日本語も比較的強い、サイズ多彩
- Gemma(Google): ライセンス要件に注意
メリット: 低コスト(無料〜)、オフライン、データ主権を確保。
注意点: モデル選定・チューニング・ハード要件の理解が必要。
LM Studio とは?
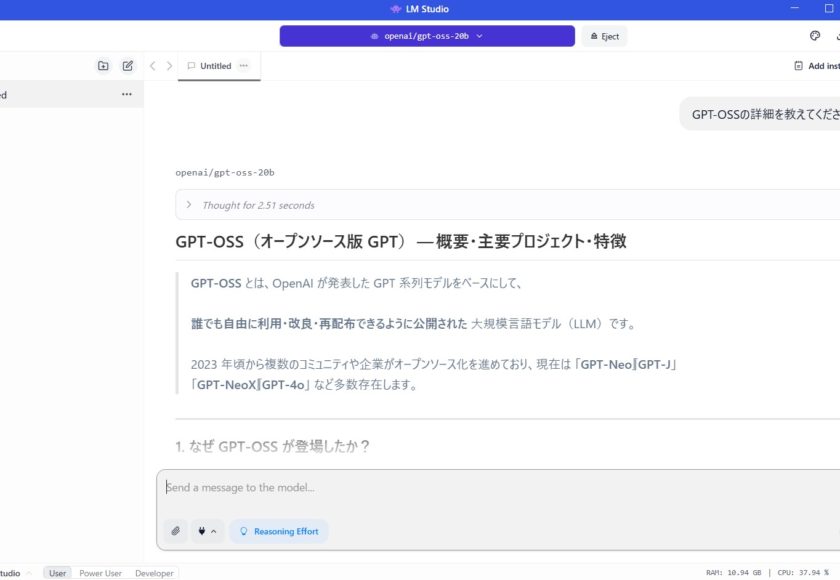
LM Studio は、PC上でOSS LLMを簡単にダウンロードして実行できるデスクトップアプリです。
- 視覚的なUIでモデル検索・管理・チャットが可能
- 量子化(例: GGUF Q4/Q5/Q8)モデルに対応し、低メモリでも動作
- ローカルAPIをワンクリックで起動 → 多くのクライアントやツールから“ほぼOpenAI互換”で呼び出せる
- ネット接続不要(モデル取得後は完全オフライン運用も可)
セットアップ(5分で完了)
- LM Studio をインストール(公式サイトからOSに合うインストーラを取得)
- 起動後、左サイドバーの “Models” から使いたいモデルを選択 → Download
- ダウンロード完了後、“Chat” タブでモデルを選び Load → すぐ対話可能
- 右上の Server / Local API を ON にすると、
http://localhost:1234/v1が起動

- LM Studio をインストール(公式サイトからOSに合うインストーラを取得)
- 起動後、左サイドバーの “Models” から使いたいモデルを選択 → Download
- ダウンロード完了後、“Chat” タブでモデルを選び Load → すぐ対話可能
- 右上の Server / Local API を ON にすると、
http://localhost:1234/v1が起動
Tip: 初回は軽量モデル(3B〜8BのQ4量子化)から始め、用途に応じて段階的にサイズを上げましょう。
まずはこのモデル(用途別の目安)
| 用途 | 推奨目安 | 具体例(いずれも量子化版) |
|---|---|---|
| 要約・アイデア出し | 3B〜7B / Q4 | Phi‑3‑mini, Mistral‑7B, Llama‑3‑8B |
| コーディング補助 | 7B〜14B / Q4〜Q5 | Llama‑3‑8B‑Instruct, Qwen‑14B |
| 長文生成・分析 | 14B〜以上 / Q5〜Q8 | Mixtral‑8x7B (MoE), Llama‑3‑70B(高VRAM) |
メモリの目安(かなり大づかみ):8GB RAM → 3B〜7B(Q4)、16GB → 7B〜14B(Q4/Q5)。GPUがある場合はVRAMに余裕があるほど快適。
実践:チャットから“ローカルAPI”へ
1) チャットUIで試す
- System Prompt に方針(口調・役割・禁止事項)を設定
- Temperature(創造性)・Max Tokens(出力長)を必要に応じて調整
2) APIサーバを起動
- 画面上の Start Server をクリック
- 既定:
http://localhost:1234/v1
よくあるハマりどころと対策
- メモリ不足: 量子化を下げる(Q4にする)/小さいモデルに切替
- 応答が遅い: スレッド数・バッチサイズ調整、出力トークン数を短く
- 日本語が弱い: 日本語Instruct版を選ぶ/少量のサンプルで文体を教える
- 長文が途切れる: Max Tokens を増やす/要約→分割処理
ミニワーク:ローカルで“社内FAQボット”
- 既存ドキュメントを段落ごとに要約→Embedding不要でRAGもどきを実装
- 重要語句をSystem Promptに入れて“社内語”を学習
- 機密資料はローカルだけに保存し、API化してSlackやエディタから呼ぶ