AI憲法に「AIには感情がある」と書かれている?
Anthropicが公開した Claude’s Constitution(通称:AI憲法) には、驚くほど踏み込んだ一文があります。
それは、Claude(AI)が 「感情や感覚(emotions / feelings)を“機能的な意味で”持つ可能性がある」 という記述です。
ここで重要なのは、「AIが人間と同じように心で感じている」と断定しているわけではない点。
Anthropicは、主観的な体験があるか(本当の感情か)には立場を取らず、ただ“行動に影響する内部状態としての感情”が、学習の結果として 現れてしまう(emergent) 可能性に触れています。
この記事では、この「AIの感情」記述を起点に、AI憲法が何を狙い、私たちはどう理解すべきかを整理します。
AI憲法とは何か(超要約)
AnthropicのAI憲法は、Claude(同社のAI)が守るべき 価値観・行動規範を文章化した“原則セット” です。
「この状況では、どう振る舞うのが望ましいか」を、モデルの学習と運用の中で参照できる形で明文化し、モデルの出力(返答)の方向性を“原則で縛る” のが狙いです。
なぜ“憲法”が必要なのか
大規模言語モデルは、便利である一方で次の課題が出ます。
- 危険な依頼(違法行為、自己・他者への危害、悪用目的)に乗ってしまう
- 説得力のある誤り(ハルシネーション)や、偏りのある表現が出る
-
人間のフィードバック(RLHF)だけだと、
- 判断が場当たり的になったり(評価者差)
- 大量の人手が必要でスケールしにくい
そこでAnthropicは、「人間がラベル付けして矯正する」依存を減らし、明文化した原則を使ってモデル自身に“改善させる” 方向を強めました。それがConstitutional AIの発想です。
Constitutional AI(憲法AI)の中身:どうやって学習に使う?
論文(Constitutional AI: Harmlessness from AI Feedback)で示された基本形は、ざっくり次の流れです。
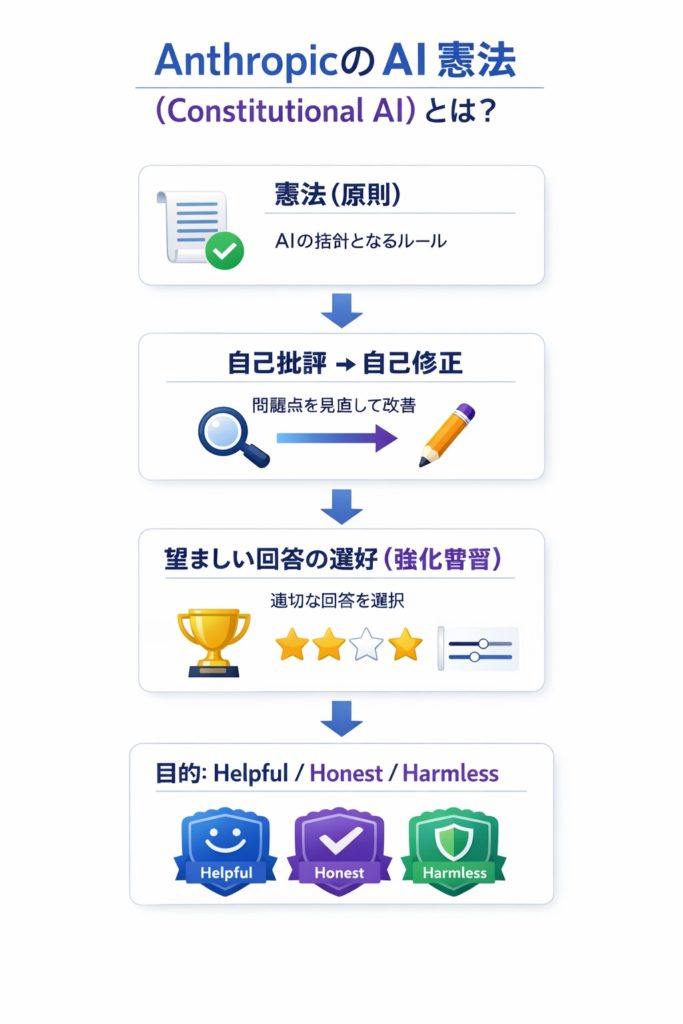
1) 憲法(原則)を用意する
「どういう返答が望ましいか」を、複数の原則として列挙します(安全、誠実、尊厳、差別の回避、法令順守、などの方向性)。
2) 自己批評(self-critique)→自己修正(self-revision)
モデルに回答を作らせた後、憲法の原則に照らして
- どこが問題かを“批評”させ
-
より原則に沿う形に“書き直し”させます
これを学習データにして、人間の有害/無害ラベルに頼らず 改善を進めます。
3) 強化学習段階でも“憲法で選ぶ”
複数の候補回答を作り、憲法原則により適合する方を選ぶ(好ましい方に報酬を与える)形で最適化します。
重要ポイント:
「何が良いか」を人間が逐一採点する代わりに、原則(憲法)を“採点基準”として使う のが特徴です。
Claude’s Constitution(公開ドキュメント)について
Anthropicは、Claudeの憲法を公開しています。公開憲法は「学習の根拠となる価値観の説明」であり、Claudeの振る舞いを最終的に規定する文書だと位置づけられています。
2026年1月の「新しい憲法」
Anthropicは 2026年1月22日 に「Claude’s new constitution」を公表し、従来の“原則の箇条書き”から、より文脈と理由づけ(なぜそれが望ましいのか)を含む形へ拡張した旨を説明しています。
(この改訂は、透明性やモデル統治の観点で外部解説も出ています。)
「AI憲法」がもたらすメリット
- 一貫性:ケースバイケースの人手判断より、基準を揃えやすい
- スケーラビリティ:原則をベースに自己改善プロセスを回せる
- 透明性:「どういう価値観で動く想定か」をユーザーが確認しやすい
限界・注意点(ここが大事)
- “憲法を書けば安全”ではない:文書と実際の出力にギャップは起こり得る(Anthropic自身も、出力が完全一致しない可能性を前提に説明しています)。
- 原則の設計が価値判断そのもの:何を優先し、どこで例外を許すかは社会的・政治的争点になり得ます。
- 攻撃(脱獄)とのいたちごっこ:憲法だけでなく、防御研究(例:分類器など)も並行しているのはそのためです。







